Estimated Reading Time: 10 minutes
The Wild world of fine-tuning large language models is where we feed math problems to a 7-billion-parameter beast (Qwen2.5-7B-Instruct), run it on 8 fire-breathing A100 GPUs, and politely ask it to get smarter without throwing a tantrum. This writeup dives into GRPO, a Reinforcement Learning based training method. GRPO helps the model learn by generating answers, scoring them like a strict exam checker, and adjusting its thinking just enough to grow, but not so much that it forgets its roots. It’s like teaching a robot to be better at homework using rewards, rules, and a bit of controlled chaos and yes, everything is tracked in wandb, because if a training run happens without graphs, did it even happen? 🚀
Details of My Training
The main objective is to experiment with the Qwen2.5-7B-Instruct model an instruction-tuned language model with 7.61 billion parameters and 28 layers, particularly strong in code and math reasoning tasks.
Model Analysis
Pretrained Model and Memory Efficiency
We start by using the Hugging Face library to load a pretrained model. To improve memory efficiency, use torch.bfloat16 instead of the usual 32-bit float format. Here’s a brief explanation:
- Float32: Uses 32 bits per number (1 sign bit, 8 exponent bits, and 23 mantissa bits).
- BFloat16: Uses only 16 bits per number (1 sign bit, 8 exponent bits, and 7 mantissa bits).
BFloat16, often referred to as “brain float,” retains the full exponent range of Float32. This allows it to represent both very large and very small values reliably unlike the standard float16, which has a limited exponent range and can suffer from underflow or overflow. The significant reduction in memory usage (16 bits per value) also leads to faster VRAM transfers. The trade-off is a slight drop in precision, which remains within acceptable limits for most models.
Tokenizer Setup
After downloading the model using from_pretrained, we obtain the tokenizer via Hugging Face’s AutoTokenizer. We specifically set padding_side="left", which means that when padding sequences to a uniform length, the padding tokens are added to the beginning of the sequence. This approach is particularly beneficial for many decoder-based models, which tend to work best with left padding.
Multi-GPU Environment and Dataset Preparation
Since the training environment runs on 8 A100s or 8 H100s, we first identify the available GPUs and initialize their device IDs. The next steps involve:
- Preparing and shuffling the training dataset to ensure randomness.
- Defining an evaluation set of ~30 examples.
- Creating both training and evaluation datasets.
Evaluating the model on the evaluation set before fine-tuning (using GRPO) is crucial. This initial evaluation gives an accuracy baseline in my case, the model achieves around 63% accuracy on math problems, which is a promising start.
Optimizing Model Memory
Before training, we optimize model memory with several key steps:
- Set Training Mode: Ensure the model is in training mode.
- Disable KV Caching: For more details, read about KV Caching
- Enable Gradients on Input: Set
require_grad=Trueon the input embedding layer so that gradients propagate properly through the network during backpropagation. - Enable Gradient Checkpointing: This technique saves memory by storing only select activation checkpoints. When needed during backpropagation, the activations are recomputed on the fly, trading extra computation time for reduced memory usage. This allows larger models to be trained on limited hardware.
Let’s looking into the training configs now,
Training Configuration (GRPO)
The core of the process is setting up the training configuration for GRPO (Group Relative Policy Optimization). Here’s a breakdown of the key parameters:
- num_iterations: The total number of cycles for the outer loop. Each cycle involves creating a new reference model (a deep copy of the current policy model) and running multiple training steps.
- num_steps: Defines how many training steps will occur (e.g., 500 steps). In each step, the model samples a batch of data, generates completions, and applies GRPO updates.
- batch_size: Determines the number of prompts processed in a single training step. For example, with a batch size of 7:
- Each step generates completions for 7 prompts.
- With 12 completions per prompt over 500 steps, the model generates a total of 42,000 completions. These completions guide the model’s learning via reward scoring.
- num_generations: Specifies that 12 completions are generated per prompt.
- max_completion_length: Sets the maximum length of a generated completion to 400 tokens.
- beta (KL penalty coefficient): Controls how much the model is penalized for deviating from the reference model. A lower value (e.g., 0.04) allows for more deviation.
- Learning Rate: Determines the size of the update to model parameters. A smaller learning rate typically contributes to more stable training.
- mu: Defines how many times the model is updated per batch of data. With mu set to 1, the model is updated once per batch.
- epsilon: Limits the extent of change in a single update by clipping the probability ratio between new and old policies to the range [0.9, 1.1].
- The Role of Beta and Epsilon Both parameters work together to stabilize training:
- Beta (KL Penalty): Acts as a “soft constraint” by penalizing the model when its predictions diverge significantly from the reference model.
- Epsilon (Clipping Parameter): Serves as a “hard constraint,” preventing any single update from causing extreme changes.
- Together, these parameters balance exploration and stability during training. For example, if the original model predicts a token with a probability of 0.3 and after an update it increases to 0.4, this change is carefully managed by these constraints.
Monitoring Training Progress
We use Weights & Biases (wandb) to monitor the training runs. It provides detailed graphs and metrics to track the model’s progress throughout the training process.
Warm Up
With the environment configured, memory optimized, and training parameters set, the next step is to dive into the fine-tuning process with GRPO. In the upcoming sections, I’ll explore the details of the grpo training function and how it drives the training process.
Inside the GRPO Training Loop
In this section, we dive deep into the fine-tuning process using GRPO (Group Relative Policy Optimization). This covers everything from model initialization to the backpropagation and optimization steps, offering a comprehensive look at how the training loop is orchestrated.
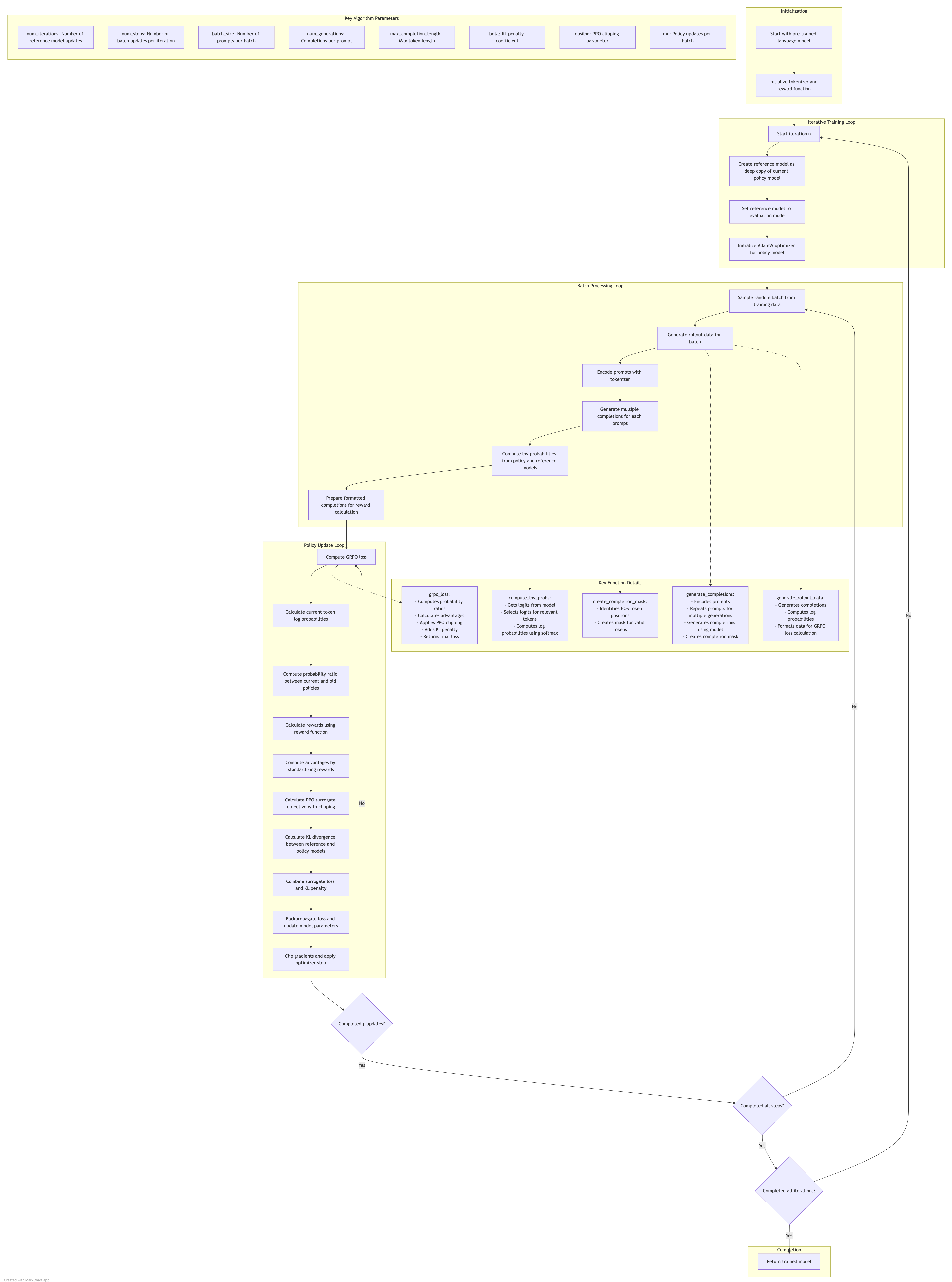
🚀 Initialization Phase
The GRPO training begins with setting up the model, tokenizer, datasets, and other configurations.
Step-by-Step:
-
Input Parameters
TheGRPO trainingfunction accepts the model, tokenizer, training data, a reward function, available device IDs, and training configuration. - Data Parallelism with 8×GPUs
The model is wrapped withDataParallelto leverage multiple GPUs efficiently:- The input batch is split into chunks and distributed across GPUs.
- Each GPU processes its portion independently during the forward pass.
- The results are gathered back and combined.
- Gradients are computed on each GPU and averaged in the backward pass.
-
Outer Loop Setup
The main training loop starts withnum_iterations(typically set to 1 for most fine-tuning sessions). - Reference Model Creation
A deep copy of the original model serves as the reference model:- It’s set to evaluation mode.
- All parameters have
requires_grad=Falsefor performance efficiency. - This model is used to compute KL divergence and maintain training stability.
- Optimizer Setup
An optimizer like AdamW is initialized, and the main model is set to training mode.
🔁 Batch Processing Loop (num_steps)
Each iteration contains multiple steps to generate data, compute rewards, and update the model.
Step-by-Step:
-
Random Sampling
A random batch is sampled from the training data. - Rollout Data Generation
Using a no-gradient context, the model generates rollouts:
- Prompt and Answer Preparation
- Completion Generation using
generate_completions:- Prompts are tokenized using left padding (better suited for decoder-only models).
- Tokenization yields:
input_ids: Numerical IDs for tokens.attention_mask: 1 for real tokens, 0 for padding.prompt_length: Used to separate prompt from generated tokens.
- Prompt Duplication: Prompts are repeated
batch_size × num_generationstimes usingrepeat_interleave. - Model Generation Settings:
do_sample=True: Enables diversity in outputs.temperature=1.0: Maintains original probability distribution.early_stopping=False: Continues until max length is hit.
- Postprocessing:
- Extracts only the generated part after the prompt.
- Creates a completion mask using EOS token positions.
- Log Probabilities Computation:
- A forward pass is done again using the full prompt + completion sequence.
- This step retrieves log probabilities from both the current model and reference model using selective log softmax.
- Completion Formatting
Converts token IDs back into human-readable text usingtokenizer.decode(...). Each decoded string is structured as:[{'content': text}]
📉 GRPO Loss Computation
Once rollout data is available, the GRPO loss is calculated and used for model optimization.
Step-by-Step:
-
Multiple Updates (mu)
For each batch,mucontrols how many times backpropagation is run. Usually, it’s set to 1. -
Loss Calculation via
grpo_loss:- Log Probabilities Update: The model computes updated token-level log probabilities.
- Probability Ratio Calculation:
- Measures how the probability of generating the same tokens has changed.
- This ratio is a key part of PPO-based algorithms.
- Reward Computation:
- Inputs: prompts, completions, and expected answers.
- The reward function returns a reward tensor.
- Advantage Calculation:
- Rewards are reshaped to
[batch_size, num_completions]. - Mean and standard deviation are computed per prompt.
- Advantages are standardized (mean-centered and scaled).
- Rewards are reshaped to
- Surrogate Loss:
- Calculated as
ratio × advantage. - PPO-style clipping is applied using the min of
surr1andsurr2.
- Calculated as
- KL Divergence:
- Measures how far the new model deviates from the reference model.
- Token-wise Loss:
- The final loss per token is computed as
surrogate_loss - beta × kl. - This is averaged over valid tokens and across the batch.
- The loss is negated to flip from maximization to minimization (as required by optimizers).
- The final loss per token is computed as
🔧 Backpropagation and Optimization
The last part of the loop applies the computed gradients to update the model.
Step-by-Step:
-
Clear Old Gradients
optimizer.zero_grad()removes previously stored gradients. -
Backward Pass
loss.backward()computes the gradient of the loss with respect to each model parameter. - Gradient Clipping
- Limits the magnitude of the gradients using
max_norm=0.1. - This is essential for stable training in reinforcement learning settings.
- Limits the magnitude of the gradients using
- Parameter Update
optimizer.step()updates model weights using AdamW:- Applies learning rate, momentum, and regularization.
- Gradually improves the model’s ability to generate better completions.
📊 Monitoring with Weights & Biases
Throughout the training process, Weights & Biases (wandb) is used to track metrics, visualize performance trends, and monitor the model’s evolution over time. Graphs showing rewards, KL divergence, and loss provide valuable insight into the training dynamics.
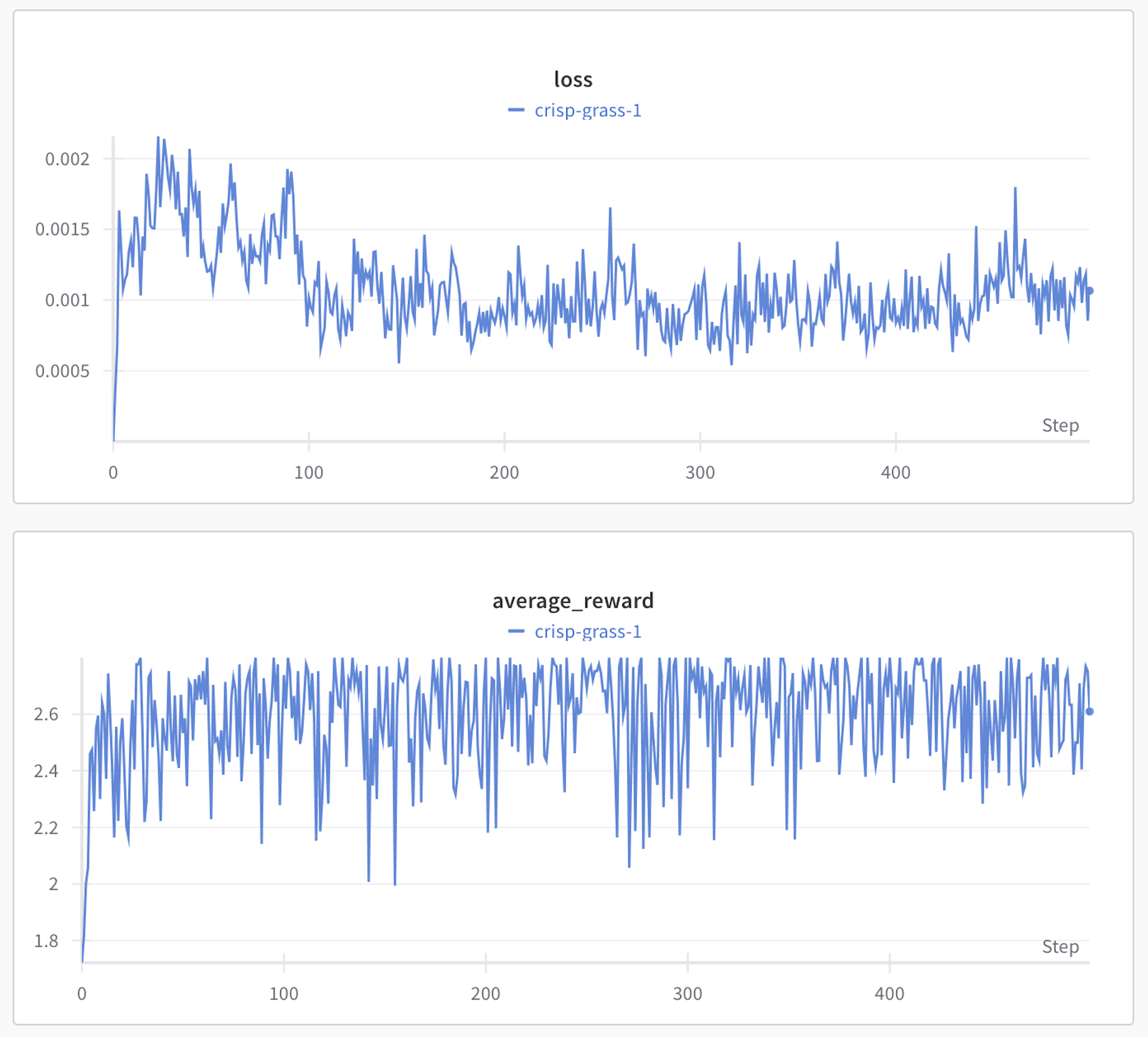
- Initial Evaluation Accuracy before GRPO: 66.67%
- Final Evaluation Accuracy after GRPO: 96.67%
✅ Summary
This deep-dive into GRPO Training reveals how large language models are fine-tuned using reinforcement learning principles. GRPO effectively balances exploration (new completions) with stability (reference model control), making it well-suited for optimizing instruction-following models at scale.
Acknowledgments
This learning journey has been shaped by the incredible contributions of the deep learning community. A heartfelt thank you to Andriy Burkov, whose insightful work on GRPO formed the foundation for everything shared above. His code served as both the learning path and the backbone of the model training process.
A huge shoutout to Lambda Cloud’s GPU instances—my go-to training environment for powerful and efficient computing.
Enriching my learning experience, that’s all that matters!