Estimated Reading Time: 7 minutes
Introduction
This write-up is A Neural Network Love Story (Spoiler: It’s Complicated), one neuron at a time – while GPT pretends not to notice!
It is my hands-on experience training a Generative Pretrained Transformer with 124 million parameters - powered by 8 massive NVIDIA A100 GPUs, each packing 80GB of memory. It’s like teaching a brainy AI with the horsepower of a rocket ship! All the reference materials are enclosed! 🚀
Training
So here’s the deal - I was on a mission to train this beast of a model without making my GPUs cry or throw memory errors. I went all in with some serious hardware and teamed it up with Distributed Data-Parallel (DDP) - think of it as the MVP of GPU teamwork. There were a few hiccups with memory at first, but nothing a bit of tweaking couldn’t fix. Locally, I tested things out with MPS (Apple Silicon rocks for that), but CUDA took the stage for the real heavy lifting. And a shoutout to Lambda Labs for making it all feel way easier than it should’ve been. Honestly, it was an awesome ride! 🚀
- Trained on FineWeb dataset (subset of it)
- 19GB
- 1.3 Trillion Tokens
- Compute
- 8× A100 (80 GB SXM4) refers to a system equipped with eight NVIDIA A100 GPUs, each with 80 gigabytes (GB) of graphics memory, using the SXM4 form factor.
- Had an awesome experience with Lambda Labs, simple to use.
- Using 8× A100 (40 GB SXM4) did not help, dealt with out of memory issues while model loading.
- Used PyTorch and Distributed Data Parallel a.k.a DDP for running 8 processes on each GPU (Rank 0 to 7)
- DDP synchronizes gradients during backward passes to speed up training and reduce communication overhead. The tutorial covers the basic use case, comparing DDP with DataParallel, and walks through setting up process groups, handling skewed processing speeds, checkpointing, and combining DDP with model parallelism for large models.
- Refer the following document for understanding GPU’s.
-
I have used MPS (Metal Performance Shaders) on Apple Silicon locally for testing and CUDA for training purpose respectively.
- Batch Size
- The total target batch size (TB) is 524,288 tokens (which is 0.5M tokens, or 2^19).
- We need to work with a batch size of around 0.5 million tokens so that we can train the model efficiently, similar to GPT-3 Small. However, our available memory can’t handle a batch size that large all at once. To work around this, we use a method called gradient accumulation.
- Micro Batch size in each micro step is B = 64
- With Sequence or Context Length T = 1024
- The total target batch size (TB) is 524,288 tokens (which is 0.5M tokens, or 2^19).
- Gradient Accumulation Steps
- is TB // (B * T * DDP_WORLD_SIZE)
- It is the number of steps to accumulate gradients over, basically do 32 forward backward passes and then do the optimizer step in this case.
- Set torch.set_float32_matmul_precision(‘high’)
- Set the float32 matrix multiplication precision to “high”.
- Although high precision can theoretically boost throughput by 8x, in practice, since float32 is still being used in memory-bound areas, the real speedup is around 1.2x.
- Define Model
- As, GPT(GPTConfig(vocab_size=50304)), 50304 is the padded vocab size, a beautiful number.
- It is not good to have vocabulary size of 50257 (used initially), we always need a beautiful number like 2 to the power for ensuring the tensor cores are best used.
- Config Parameters
- n_layer: int = 12 # number of layers
- n_head: int = 12 # number of heads
- n_embd: int = 768 # embedding dimension
- Use the Torch Compile
- torch.compile(model), in which the kernel fusion is one of the optimizations that can be automatically applied.
- Kernel fusion combines multiple operations (like matrix multiplication, activations, etc.) into a single, larger kernel, reducing memory access and computational overhead. This leads to improved performance by minimizing the cost of launching separate GPU or CPU kernels and streamlining execution.
- Enable DDP
- like, model = DDP(model, device_ids=[ddp_local_rank])
- so every local rank (gpu) will have a copy of the model, and they will communicate with each other, the forward pass goes through simply and during the backward pass, the gradients are communicated across the GPUs to get average and then each rank holds the average gradient (all reduce operation).
- Later the optimizer step is done on each GPU.
- Learning rates and Steps
- max_lr = 6e-4
- Taken from GPT3
- min_lr = max_lr * 0.1
- warmup_steps = 715
- 375e6/219, 375 million tokens, 219 tokens per batch (375 is from the gpt3 paper)
- max_steps = 19073
- 10e9/219, 10 billion tokens, 219 tokens per batch
- max_lr = 6e-4
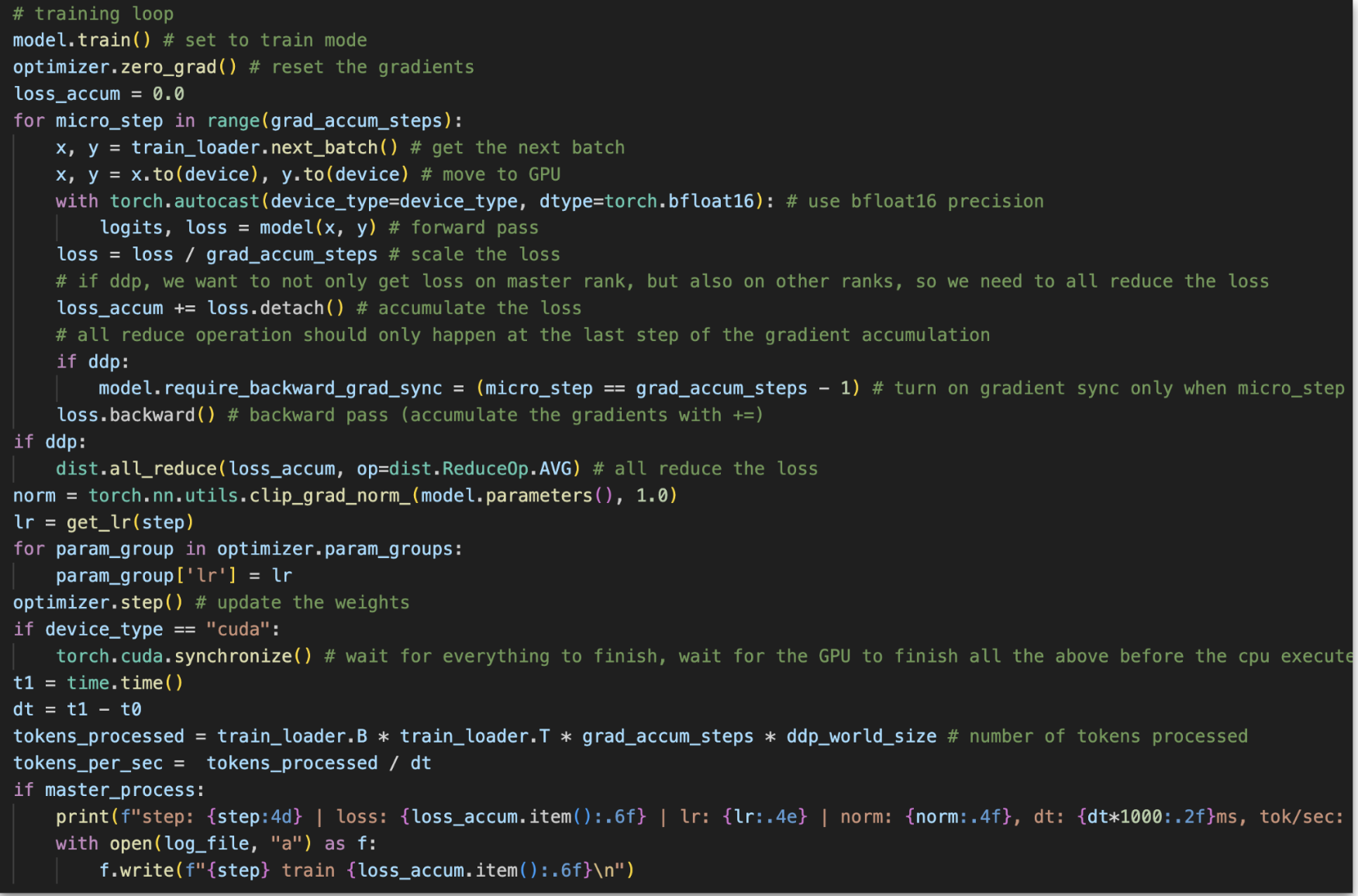
Training Loop: Marathon of Magic 🏃♂️✨
Here’s the training loop in action—like a marathon where every step counts. We’ve got 19,073 steps to greatness, and each one goes something like this:
- Reset the starting line: Zero those gradients—fresh start, every time.
- Batch prep: Grab the next data batch, suit it up for the GPU, and sprinkle on some bfloat16 magic (it’s like putting on the perfect running shoes).
- The main event: Forward pass, scale the loss (small bites are easier), and let the loss stack up like points on a scoreboard. 🏆
- Backtrack smartly: A backward pass to update what we’ve learned, with a touch of gradient clipping (1.0 max, because wild gradients aren’t fun).
- Keep it smooth: Adjust the learning rate so our model doesn’t freak out or snooze off. 💤
- Bulk up: Update those weights—stronger, better, faster. 💪
- Show off: Print the progress because what’s a race without bragging rights?
And that’s how every step of the loop takes us closer to model nirvana! 🚀

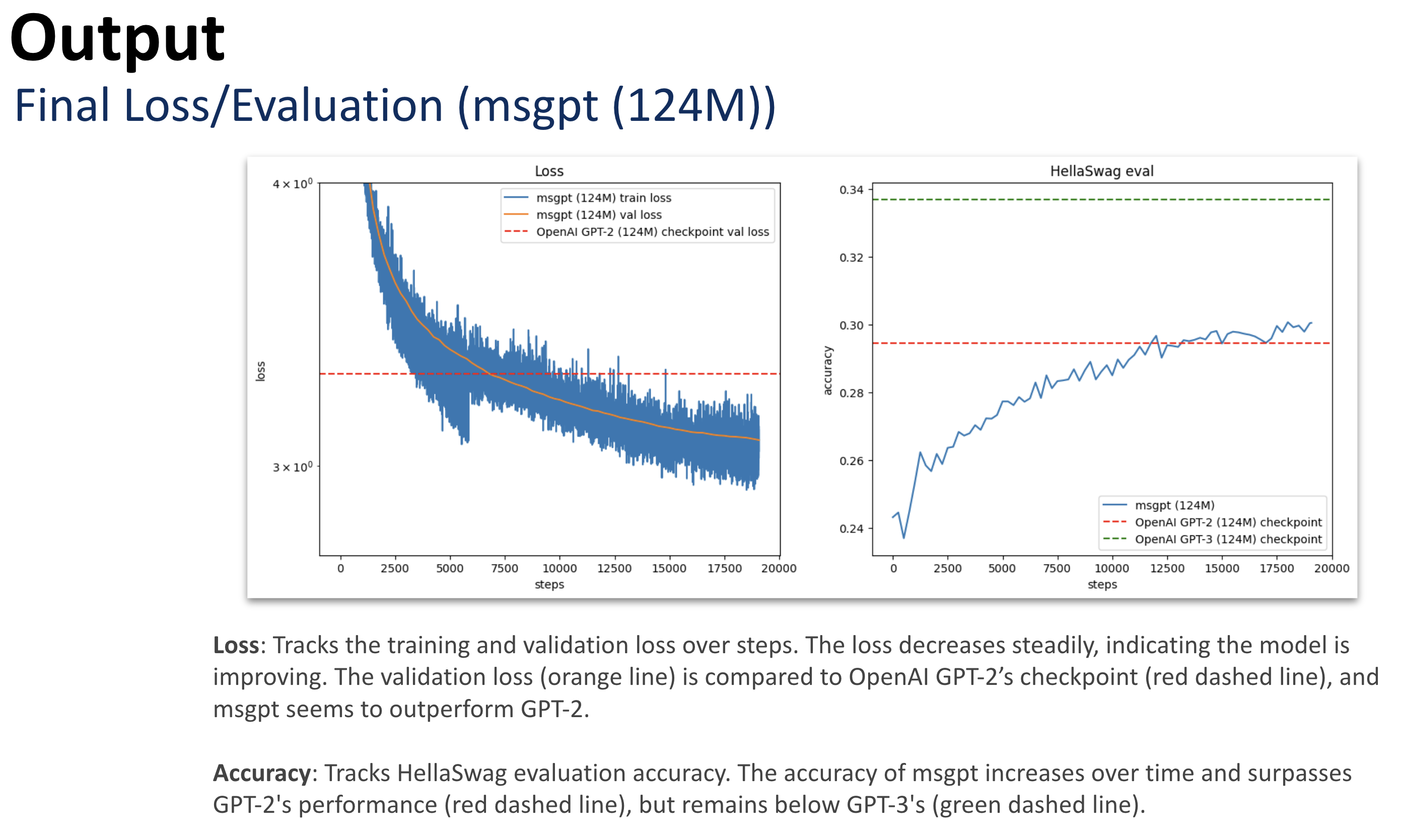
Training Output: Loss Meets Glory 🎉
-
Loss Plot (Left): Watch as the training and validation loss take a glorious dive over time! The validation loss (orange line) flexes its muscles, outperforming OpenAI GPT-2’s checkpoint (red dashed line). MSGPT is clearly the underdog-turned-superstar here. 📉🔥
-
Accuracy Plot (Right): Accuracy struts its way up, starting humbly and eventually surpassing GPT-2 (red dashed line). It’s not quite at GPT-3 levels yet (green dashed line), but hey, the journey is all about progress, right? MSGPT is on the rise! 🚀
Loss is shrinking, accuracy is climbing, and MSGPT is out here making a name for itself—GPT-2, you’ve got competition! 🎯
Inference: Generate Tokens
Ready to see the magic in action? Grab the model checkpoint, fire up generate_tokens.py, and let the tokens flow—time to turn code into creativity! 🚀✨
- Following is the Model Checkpoint
- Use the generate_tokens.py to get the output.
- Try your hands on it, follow the code
Acknowledgments
This learning journey has been profoundly influenced by numerous works and individuals in the deep learning community. I am especially grateful to fast.ai and Jeremy Howard for giving the initial inspiration and foundation to dive into deep learning. Their practical and accessible approach to AI education provided the kickstart I needed to explore this exciting field.
The seminal paper “Attention Is All You Need” by Vaswani et al. served as a key inspiration, offering a deep understanding of transformer models. Andrej Karpathy’s contributions to neural networks are instrumental in shaping my perspective. I followed his work end to end, which motivated me to learn from him and run the experiments documented here. The insights from FlashAttention and FlashAttention-2 were crucial in understanding efficient attention mechanisms. The exploration of techniques like online normalizer calculation for softmax and GELUs added depth to my understanding of optimization methods.
NVIDIA’s Tensor Core GPU architecture, particularly the A100, along with Lambda Cloud’s GPU instances, played a vital role in my hands-on learning by enabling the practical exploration of these models. Thanks to the OpenAI team for making the GPT-2 model and its codebase publicly available, which provided a valuable reference.
All these contributions have enriched my learning experience, that’s all that matters!
Resources
- MS Github Repo
- GPT (One Step at a Time)
- Attention Is All You Need
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Online normalizer calculation for softmax
- GAUSSIAN ERROR LINEAR UNITS (GELUS)
- gpt-2/src/model.py at master · openai/gpt-2 · GitHub
- NVIDIA A100 Tensor Core GPU
- Programming Tensor Cores in CUDA 9 NVIDIA Technical Blog
- NVIDIA A100 Tensor Core GPU Architecture
- Getting Started Guide — Lambda Cloud GPU Instances